本文將介紹使用python進行網頁爬蟲。
pip install beautifulsoup4
pip install lxml
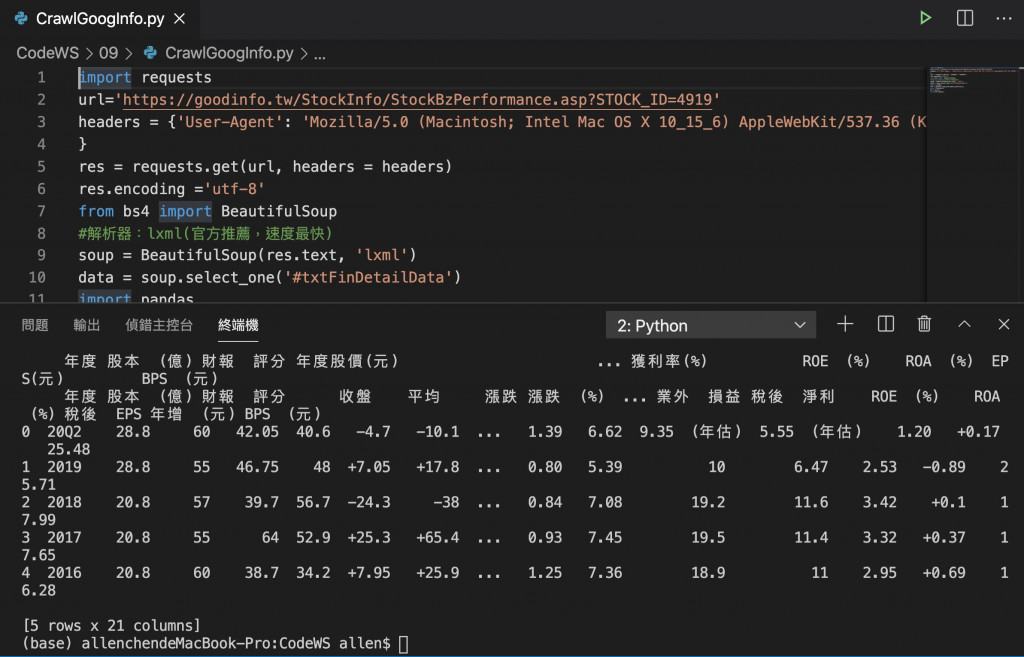
import requests
url='https://goodinfo.tw/StockInfo/StockBzPerformance.asp?STOCK_ID=4919'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36'
}
res = requests.get(url, headers = headers)
res.encoding ='utf-8'
from bs4 import BeautifulSoup
#解析器:lxml(官方推薦,速度最快)
soup = BeautifulSoup(res.text, 'lxml')
data = soup.select_one('#txtFinDetailData')
import pandas
dfs = pandas.read_html(data.prettify())
print (len(dfs))
df = dfs[1]
print(df.head())